Text Data
1) Text data description
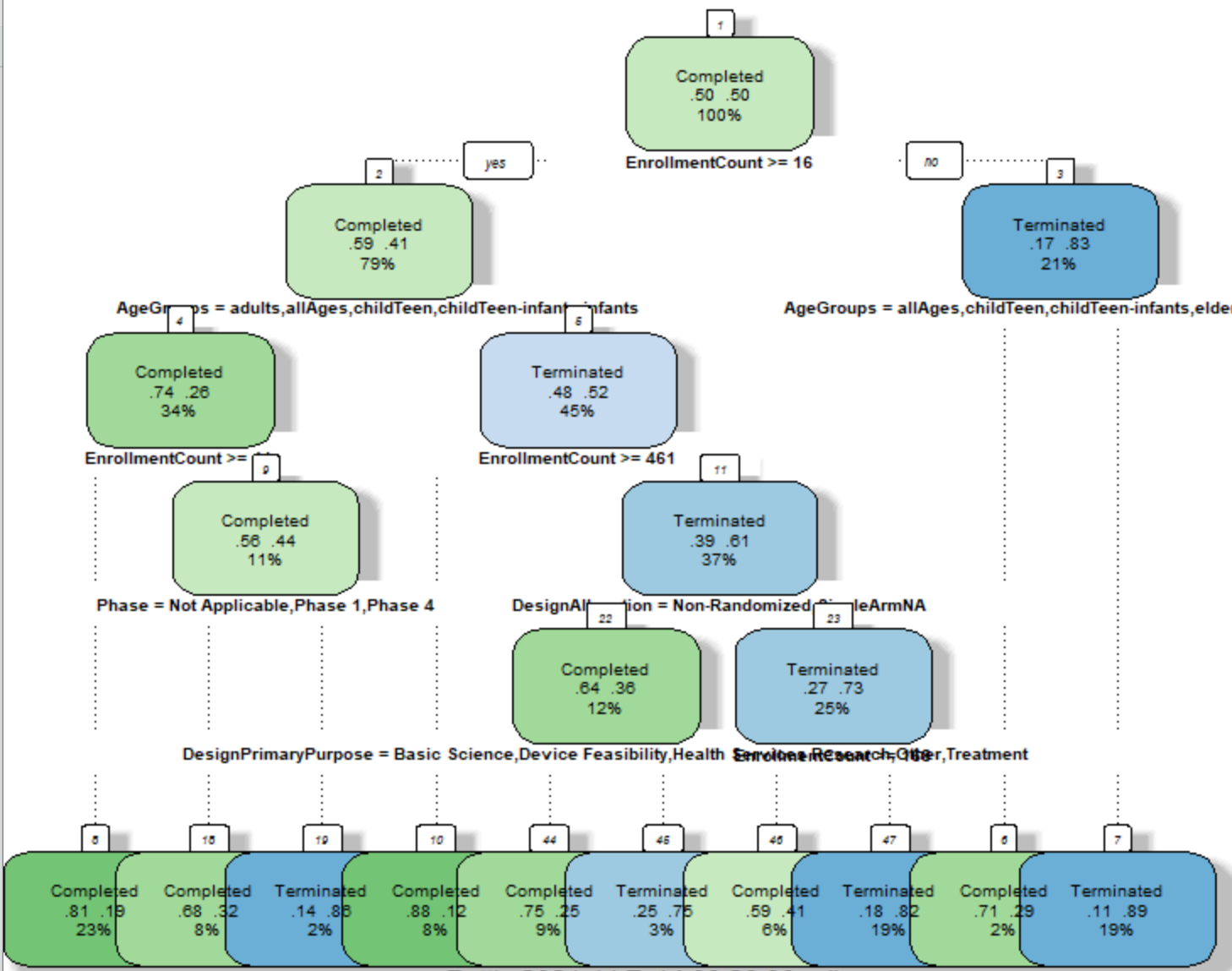
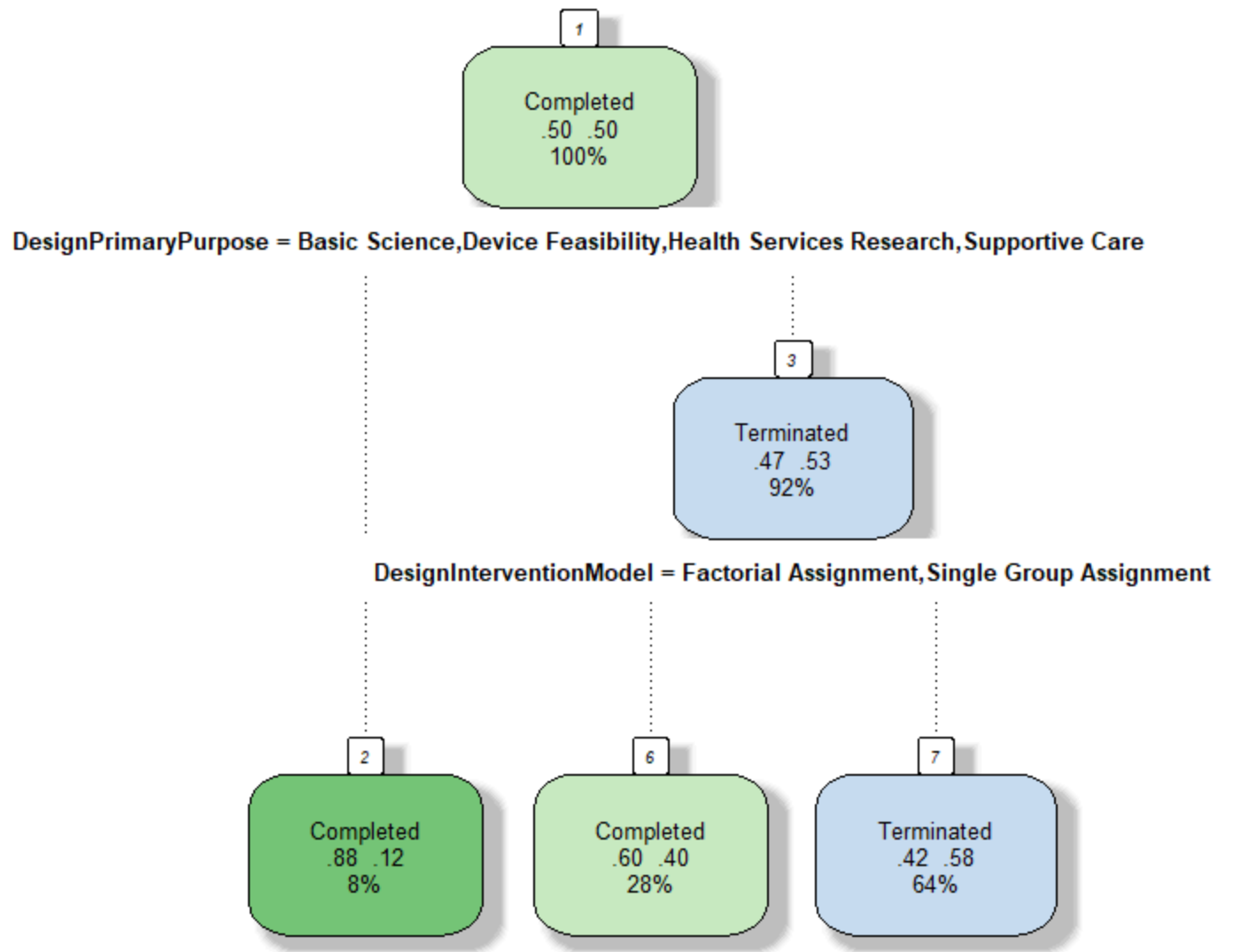
The text data presents the description of 125 clinical trials coming from 4 different bacterial infection conditions, cirrhosis, sepsis, covid and meningococcal. The dataset has 2 columns, one is label and another is the text. This dataset is a subset of collected data in Data Gathering part. The text data are transformed into matrix of token counts.
Orignial text data
Matrix of token counts
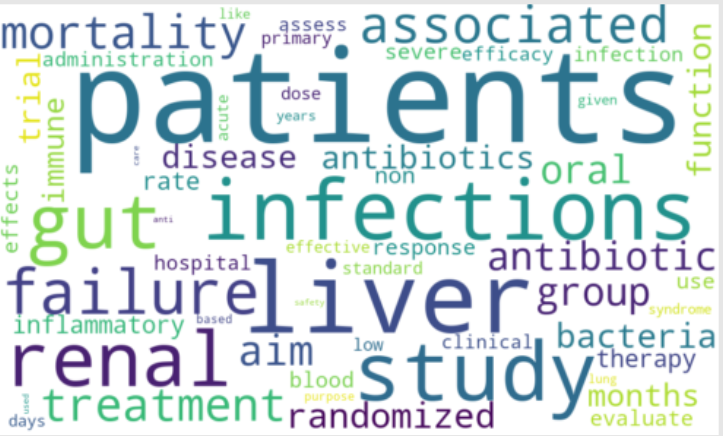
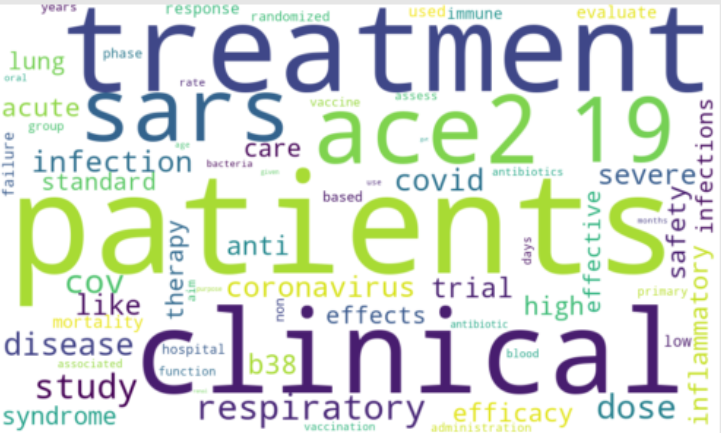
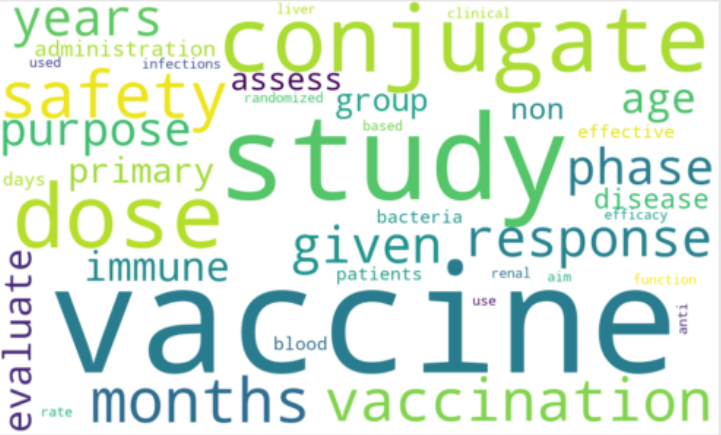
2) WordCloud of Text Data

3) Decision Trees of Text Data
Three trees are created with different parameter values. The first tree has criterion of entropy and the best
split. The second tree is set on criterion of Gini
and best
splitter.
And the third one has the criteria gini
, random splitter
and max depth of 5. Since the third tree has the limit on max depth, it has smaller size than other 2.
The first two trees presents all pure child nodes. What is more, the first tree and the second tree share a common root node vaccine
. The word liver
appears in high level in all these three trees. It clearly distinguish covid
from other three labels.
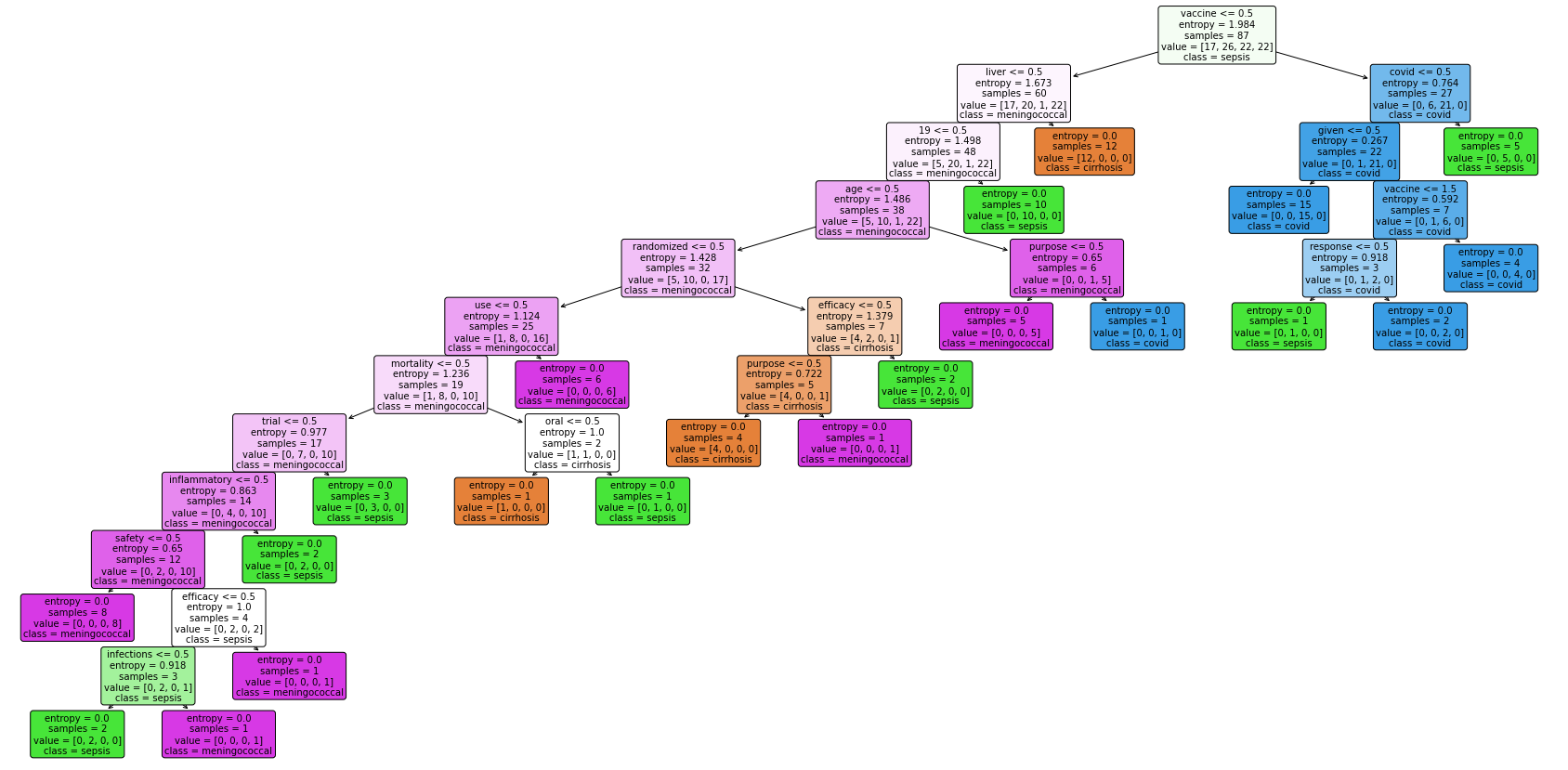
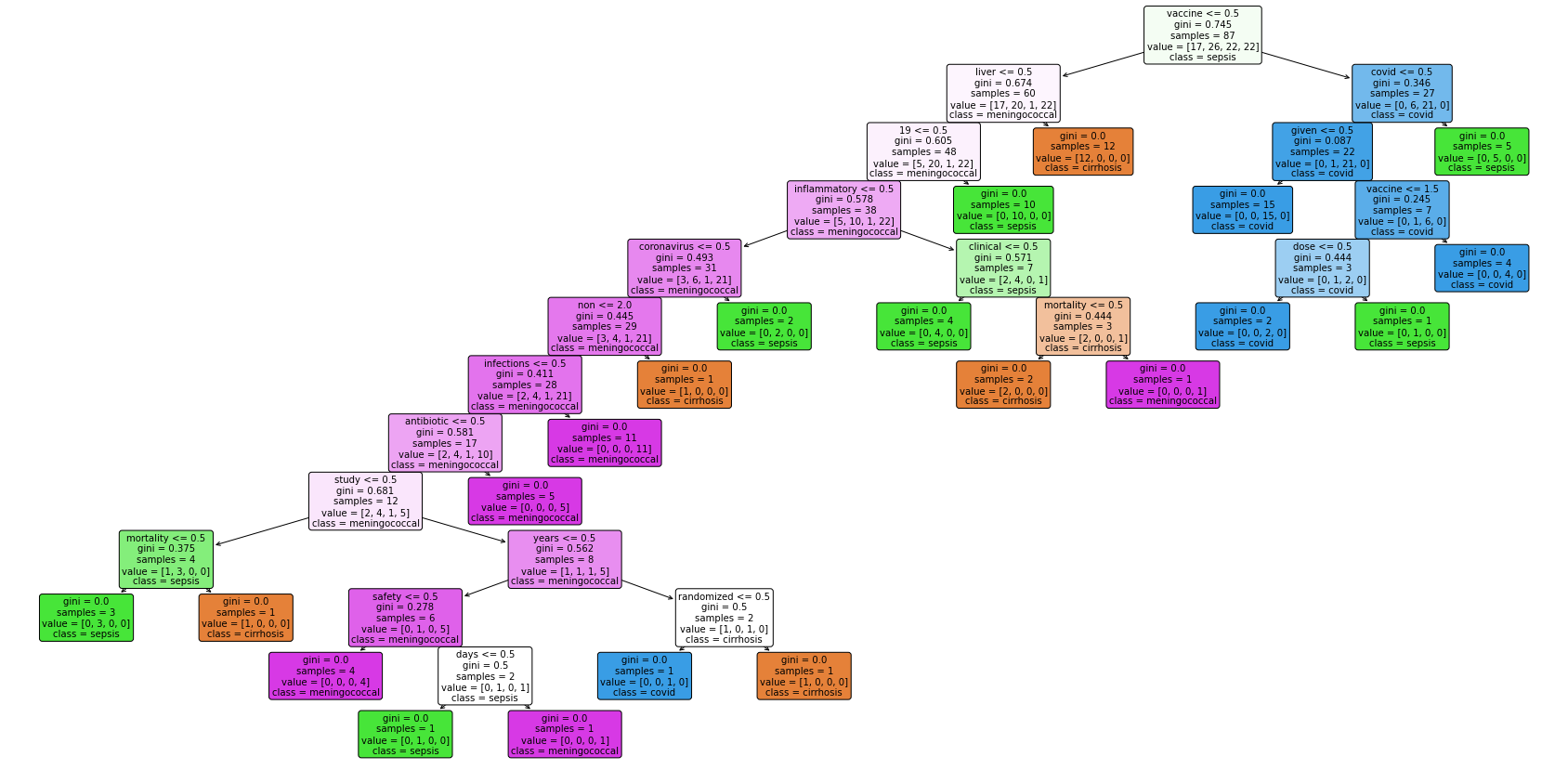
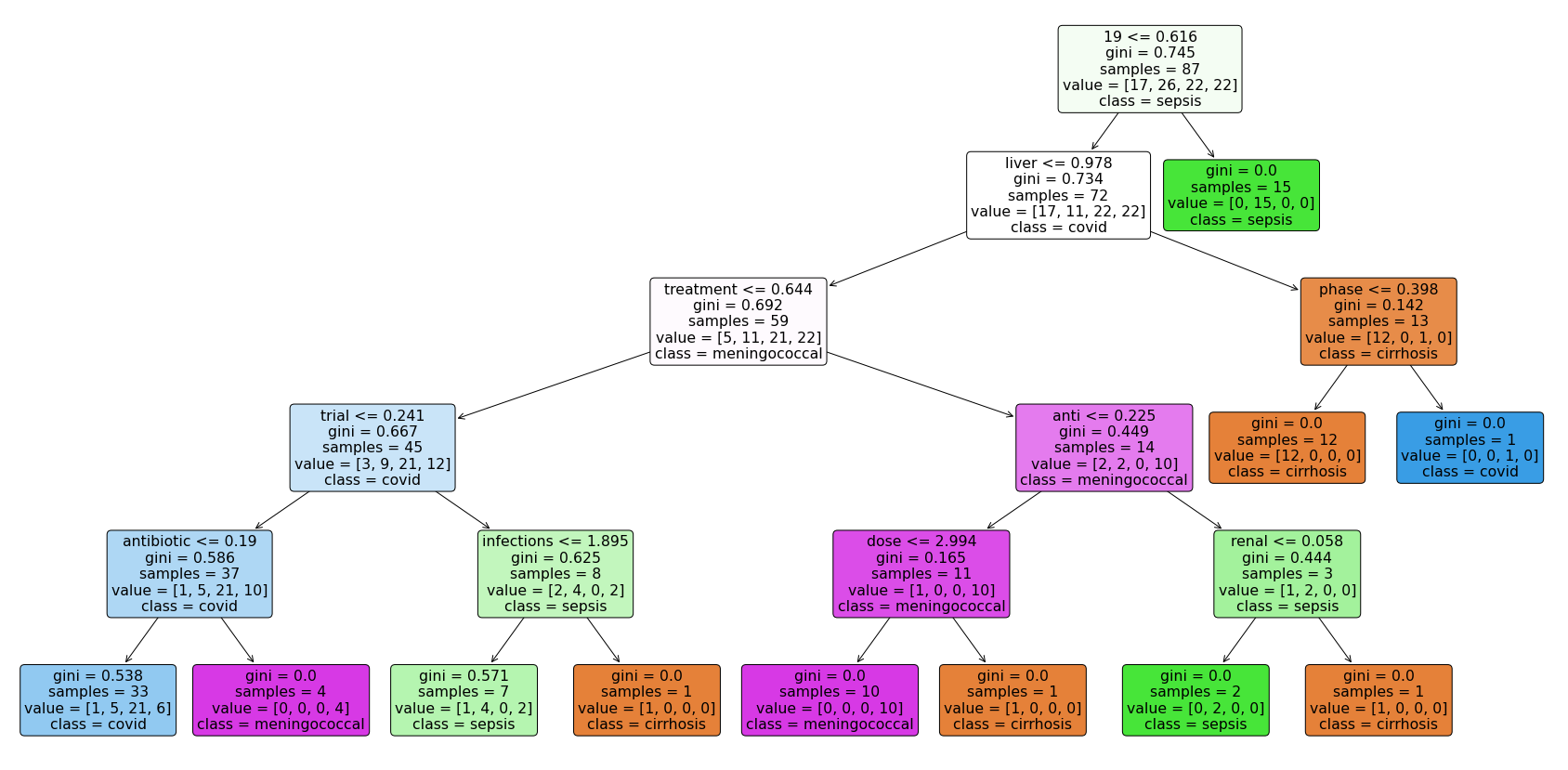
Each tree has its own confusion matrix. Generally, all three trees has good prediction on label cirrhosis
and label covid
, while relatively poor on sepsis
and least on meningococcal
.